
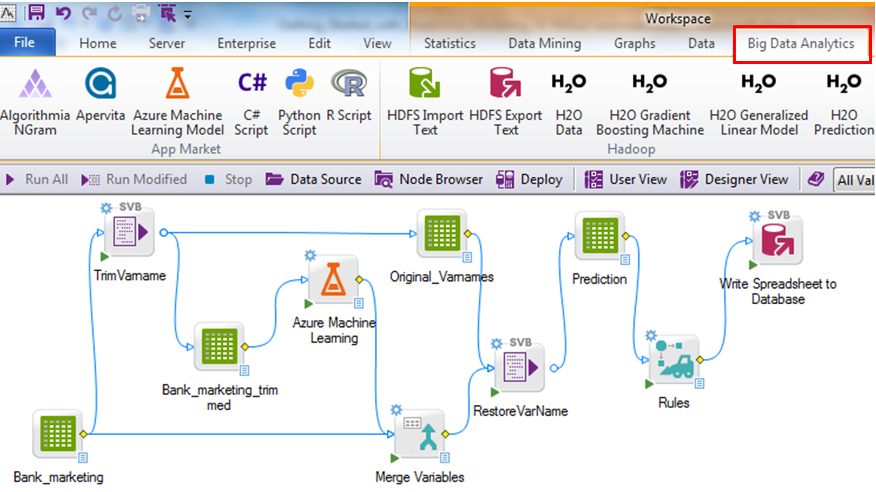
Verzi Comprehensive aplikace Statistica využijete především k analýze velkých (big data) souborů, k tvorbě pokročilých prediktivních modelů a monitorování výroby v reálném čase.
To vše v souladu se zavedenými průmyslovými standardy. Součástí balíčku je řada nástrojů strojového učení, AI a ETL.
Verzi Comprehensive využijí především datoví vědci a analytici pro predikci a modelování chování proměnných za různých podmínek a import vytvořených modelů a procesů do aplikací třetích stran.
Software je k dispozici v serverové formě.
Bez nutnosti zadávat platební údaje
Import dat
Data Scientist je plně kompatibilní se soubory xlsx (včetně xls), csv a s daty s pevnou šířkou (např. v textových souborech). Umožní vám:
- načítat data z SQL, NoSQL a dalších databází,
- pomocí integrovaného PI konektoru načíst data z OSIsoft PI systému (oblíbené řešení pro správu provozních dat),
- importovat Spotfire SBDF datové soubory,
- integrovat dva a více datových setů do jednoho grafického prostředí a série výstupů.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Příprava dat
Data Scientist nabízí automatizované očištění dat od duplicitních, nekonzistentních a odlehlých hodnot (popř. jejich překódování) pomocí tzv. Data Health Check (DHC) funkce.
Pro pokročilou datovou transformaci slouží nástroj Rules Builder, který vám umožní data z různých zdrojů zpracovat podle komplexních pravidel (i s využitím podmiňovacích výrazů).
Pro snazší zpracování přiblížíte svá data k normálnímu rozložení využitím zabudované Box-Coxovy transformace.
Vyhodnocení dat
Ve verzi Data Scientist vyhodnotíte naměřená data (včetně big data souborů) mj. pomocí:
- klasických metod popisné, parametrické a neparametrické statistiky,
- explorační analýzy a vizualizace,
- vícerozměrných statistických metod pro organizaci a klasifikaci dat,
- pokročilých lineárních a nelineárních modelů,
- odhadu mnoha složek rozptylu a přesnosti v datových souborech (Variance Estimation and Precision).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
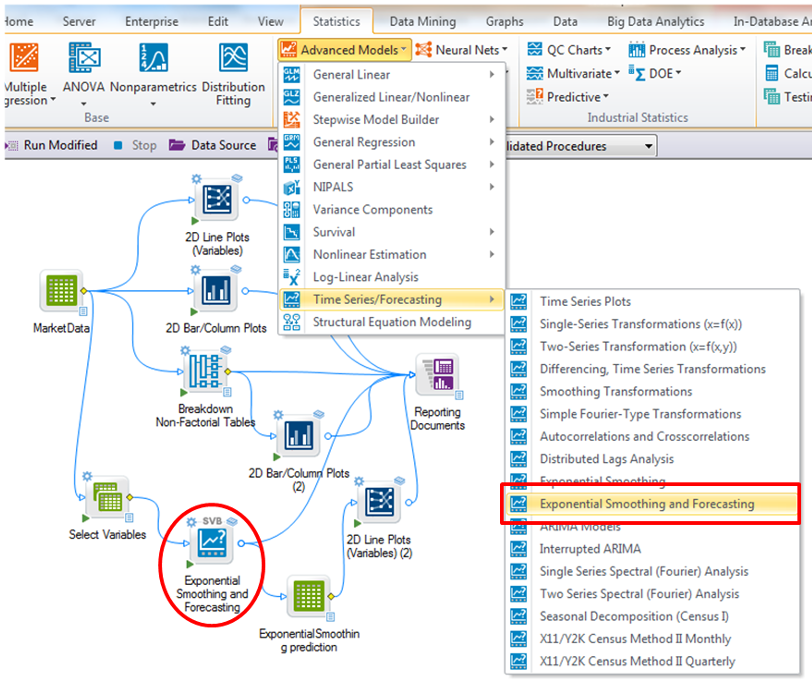
Prediktivní modelování
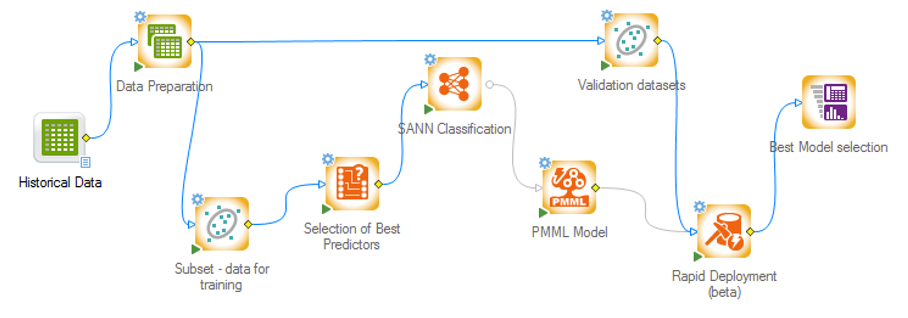
V aplikaci vytvoříte s pomocí nástrojů data miningu, text miningu a neuronových sítí modely chování sledovaných proměnných v různých situacích.
Modely je možné vygenerovat v jazycích C, C++, C#, Java, PMML, SAS a SQL a dále upravovat podle potřeby.
Data Scientist nabízí např. také funkce rozhodovacích stromů a náhodných lesů a možnost optimalizace prediktorů.
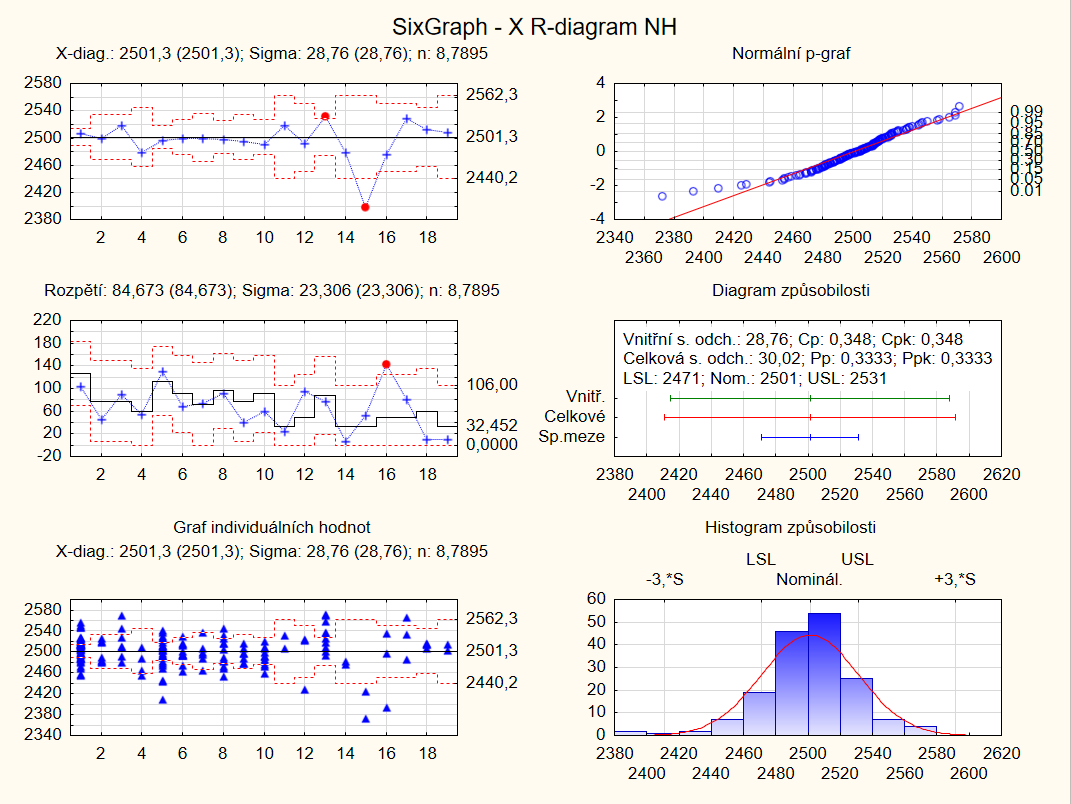
Průmyslová analytika v reálném čase
Zásadní předností Comprehensive je monitorování kvality výroby v reálném čase skrze funkce sledovatelnosti produktu (Product Traceability) a analýzy stability a životnosti (Stability and Shelf Life Analysis).
Všechny uvedené procesy probíhají v souladu se zavedenými průmyslovými standardy výroby.
Verze Comprehensive má certifikaci TIBCO ISO 9001. Její výstupy využijete ve validovaných GxP aplikacích a k podpoře směrnice FDA CFR Part 11 (resp. ekvivalentních mezinárodních směrnic ICH).
{kind=link}
{kind=link}
Další funkce
Statistica v této verzi nabízí také možnost naprogramovat si vlastní skripty v jazycích R, Python či C#. Balíček Comprehensive dále využijete např. pro:
- porozumění klíčovým parametrům ovlivňujícím kritické atributy kvality (funkce procesní analýzy, kontroly kvality a vícerozměrného statistického řízení procesů),
- návrh experimentů a jejich virtuální provádění (funkce designování experimentů – Design of Experiments, analýza síly testu – Power Analysis a odhad intervalu – Interval Estimation),
nasazení vytvořených procesů a modelů do aplikací třetích stran (s autonomní funkčností nezávislou na TIBCO Statistica).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Vizualizace a výstupy
Rozložení získaných dat a výsledky zobrazíte ve verzi Comprehensive mj. prostřednictvím histogramu, přímek, krabicových, bodových, rozptylových a kvantilových grafů a dalších často využívaných metod 2D i 3D zobrazení.
Získané výsledky může vyexportovat např. v podobě:
-
jednoduchých i pokročilých reportů,
-
zápisu do různých typů databází,
-
souborů MS Word (docx), MS Excel (xlsx) a textových souborů (csv), či pdf.
Přehled analytických funkcí
- ANOVA/MANOVA
- Association Rules
- Automated Neural Networks
- Boosted Tree
- Calculators; Distributions, Pearson Product Moment Correlation Coefficient, Six Sigma
- Canonical Analysis
- Classification Trees
- Cluster Analysis
- Correlation
- Correspondence Analysis
- Cox Proportional Hazards Models
- Data Miner Recipes
- Descriptive Statistics
- Design of Experiments (DOE)
- Discriminant Function Analysis
- Distribution Fitting
- Distributions & Simulation
- Dynamic Time Warping
- Extract, Transform, and Load (analytics are used to align time based data)
- Factor Analysis
- Faster Independent Component Analysis
- Feature Selection
- Fixed Nonlinear Regression
- General CHAID Models
- General Classification and Regression Trees (C&RT)
- General Discriminant Analysis (GDA)
- General Linear Models (GLM)
- General Partial Least Squares Models (PLS)
- General Regression Models (GRM)
- Generalized Additive Models (GAM)
- Generalized Linear/Nonlinear Models (GLZ)
- Generates Predictive Models in C, C++, C#, Java, PMML, SAS, SQL Stored Procedure in C#, SQL User Defined Function in C#, Statistica Visual Basic
- Goodness of Fit, Classification, Prediction
- Independent Component Analysis
- Interactive Tree (C&RT, CHAID)
- Lasso Regression
- Link Analysis
- Log-Linear Analysis of Frequency Tables
- Machine Learning (Bayesian, Support Vectors, K-Nearest)
- Multidimensional Scaling (MDS)
- Multivariate Adaptive Regression Splines (MARSplines)
- Multiple Regression
- Nonlinear Estimation
- Nonparametric Statistics
- Power Analysis and Interval Estimation
- Multivariate Statistical Process Control (MSPC – PCA / PLS)
- Optimal Binning
- Predictor Screening
- Principal Components & Classification Analysis (PCCA)
- Process Analysis
- Process Optimization
- Quality Control Charts
- Random Forests
- Rapid Deployment of Predictive Models (PMML)
- Reliability and Item Analysis
- Sequence and Link Analysis
- Stabilty and Shelf Life Analysis (regulated by FDA)
- Stepwise Model Builder (what-if)
- Structural Equation Modeling and Path Analysis (SEPATH)
- Survival & Failure Time Analysis
- Time series / forecasting
- t-tests and other tests of group differences
- Tabulate
- Text Mining
- Variance Components & Mixed Model ANOVA/ANCOVA
- Weight of Evidence