
View Full Version Comprehensive version of Statistica can be used primarily to analyze large (big data) datasets, create advanced predictive models and real-time production monitoring.
All this in accordance with established industry standards. The package includes a range of machine learning, AI and ETL tools.
The Comprehensive version will be used primarily by data scientists and analysts for predicting and modelling the behaviour of variables under different conditions and importing the created models and processes into third-party applications.
The software is available in server form.
No need to enter payment details
Import of data
Data Scientist is fully compatible with xlsx (including xls), csv files and with fixed-width data (e.g. in text files). It will allow you to:
- retrieve data from SQL, NoSQL and other databases,
- via integrated PI connector retrieve data from OSIsoft PI system (a popular solution for operational data management),
- import Spotfire SBDF data files,
- integrate two or more data sets into one graphical environment and a series of outputs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Data preparation
Data Scientist offers automated data cleansing of duplicate, inconsistent and outlying values (or their recoding) using the so-called Data Health Check (DHC) function.
For advanced data transformation, the tool Rules Builderwhich allows you to process data from different sources according to complex rules (even using conditional expressions).
For easier processing, bring your data closer to a normal layout by using the built-in Box-Cox transformation.
Data evaluation
In Data Scientist, you can evaluate measured data (including big data files), including. with the help of:
- classical methods descriptive, parametric and non-parametric statistics,
- exploratory analysis and visualization,
- multivariate statistical methods for data organization and classification,
- advanced linear and non-linear models,
- estimation of many variance components and accuracy in the data sets (Variance Estimation and Precision).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
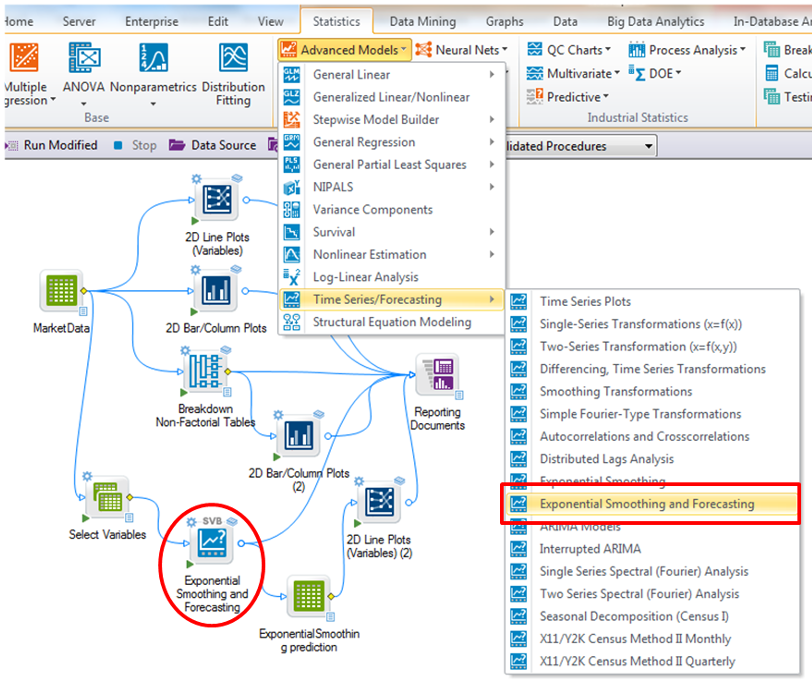
Predictive modelling
Use data mining, text mining and neural network tools to create models of the behaviour of the observed variables in different situations.
Models can be generate in C, C++, C#, Java, PMML, SAS and SQL and can be further modified as required.
Data Scientist offers e.g. also the function of decision trees and random forests and the possibility optimization of predictors.
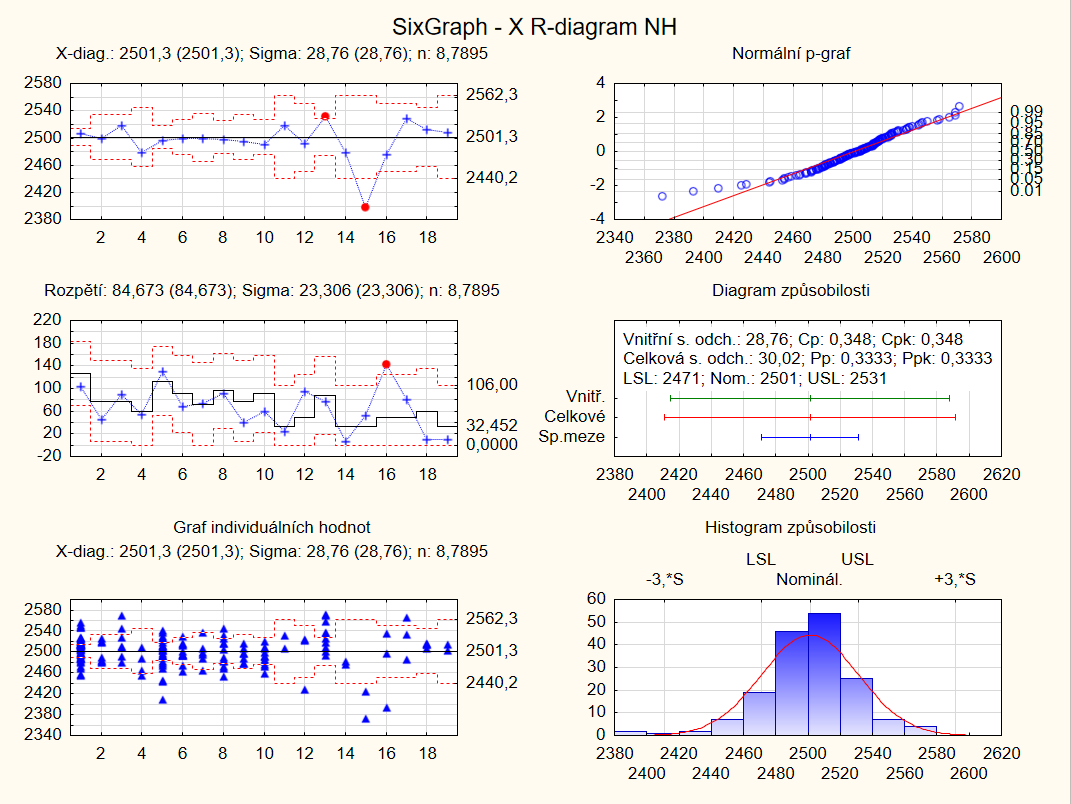
Real-time industrial analytics
The main advantage of Comprehensive is real-time monitoring of production quality through product traceability functions (Product Traceability) and stability and lifetime analysis (Stability and Shelf Life Analysis).
All of these processes are carried out in accordance with established industry standards of production.
The Comprehensive version is TIBCO ISO 9001 certified. Its outputs you can use in validated GxP applications and to support FDA CFR Part 11 (or equivalent international ICH guidelines).
{kind=link}
{kind=link}
Other features
Statistica in this version also offers the possibility to program custom scripts in R, Python or C#. The Comprehensive package can also be used for e.g. for:
- understanding the key parameters affecting critical quality attributes (process analysis, quality control and multivariate statistical process control functions),
- design of experiments and their virtual execution (design of experiments function – Design of Experiments, test power analysis – Power Analysis and interval estimation – Interval Estimation),
deployment of developed processes and models into third-party applications (with autonomous functionality independent of TIBCO Statistica).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Visualisation and outputs
In Comprehensive you can see the distribution of the acquired data and the results among others in histogram, line, box, point, scatter and quantile plots and more frequently used 2D and 3D imaging methods.
The results obtained can export e.g. in the form of:
-
simple and advanced reports,
-
entry into different types of databases,
-
MS Word (docx), MS Excel (xlsx) and text files (csv) or pdf.
Overview of analytical functions
- ANOVA/MANOVA
- Association Rules
- Automated Neural Networks
- Boosted Tree
- Calculators; Distributions, Pearson Product Moment Correlation Coefficient, Six Sigma
- Canonical Analysis
- Classification Trees
- Cluster Analysis
- Correlation
- Correspondence Analysis
- Cox Proportional Hazards Models
- Data Miner Recipes
- Descriptive Statistics
- Design of Experiments (DOE)
- Discriminant Function Analysis
- Distribution Fitting
- Distributions & Simulation
- Dynamic Time Warping
- Extract, Transform, and Load(analytics are used to align time based data)
- Factor Analysis
- Faster Independent Component Analysis
- Feature Selection
- Fixed Nonlinear Regression
- General CHAID Models
- General Classification and Regression Trees (C&RT)
- General Discriminant Analysis (GDA)
- General Linear Models (GLM)
- General Partial Least Squares Models (PLS)
- General Regression Models (GRM)
- Generalized Additive Models (GAM)
- Generalized Linear/Nonlinear Models (GLZ)
- Generates Predictive Models in C, C++, C#, Java, PMML, SAS, SQL Stored Procedure in C#, SQL User Defined Function in C#, Statistica Visual Basic
- Goodness of Fit, Classification, Prediction
- Independent Component Analysis
- Interactive Tree (C&RT, CHAID)
- Lasso Regression
- Link Analysis
- Log-Linear Analysis of Frequency Tables
- Machine Learning (Bayesian, Support Vectors, K-Nearest)
- Multidimensional Scaling (MDS)
- Multivariate Adaptive Regression Splines (MARSplines)
- Multiple Regression
- Nonlinear Estimation
- Nonparametric Statistics
- Power Analysis and Interval Estimation
- Multivariate Statistical Process Control (MSPC – PCA/PLS)
- Optimal Binning
- Predictor Screening
- Principal Components & Classification Analysis (PCCA)
- Process Analysis
- Process Optimization
- Quality Control Charts
- Random Forests
- Rapid Deployment of Predictive Models (PMML)
- Reliability and Item Analysis
- Sequence and Link Analysis
- Stability and Shelf Life Analysis(regulated by FDA)
- Stepwise Model Builder (what-if)
- Structural Equation Modeling and Path Analysis (SEPATH)
- Survival & Failure Time Analysis
- Time series / forecasting
- t-tests and other tests of group differences
- Tabulate
- Text Mining
- Variance Components & Mixed Model ANOVA/ANCOVA
- Weight of Evidence